İşlenecek ana başlıklar
Robots.txt dosyası nedir
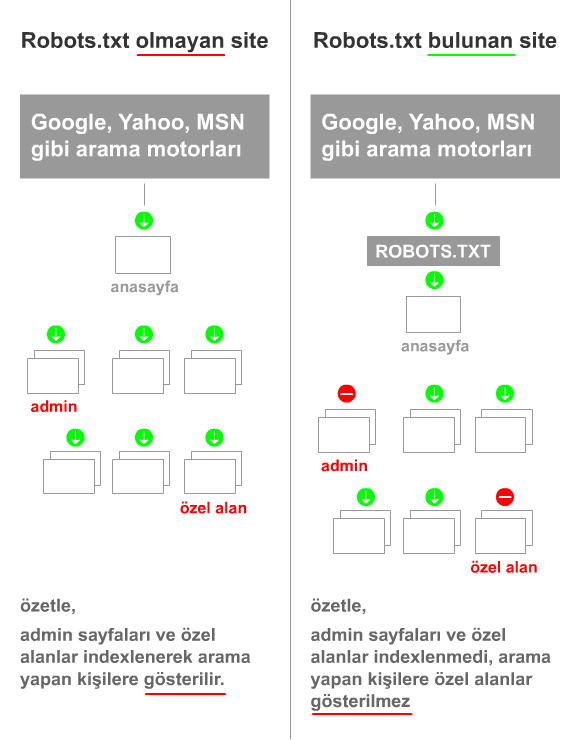
Robots.txt: Web'i tarayan arama motoru robotlarının sitenize erişimini kısıtlar. Bu botlar otomatiktir ve bir sitenin sayfalarına erişmeden önce, belirli sayfalara erişmelerini önleyen bir robots.txt dosyası olup olmadığını kontrol ederler.
Arama motorlarında arama sonuçlarında görüntülenmesini istemediğimiz içerikler varsa, robots.txt dosyasına ihtiyacınız var demektir.
Nasıl çalışır
Robots.txt elemanları
User-agent: Kuralların geçerli olduğu robot
Disallow: Engellemek istediğiniz URL
Allow: izin verilmek istenen URL
Örneklerle Daha İyi Anlayalım
Örnek 1
User-agent: * Disallow:
Kodumuzu inceleyelim. '*' bu işaretin anlamı tüm arama motorları için geçerli olduğunu gösterir. Disallow kısmı boş olduğuna göre şu yorum yapılabilir.
"Tüm arama motorları web sitenizin tüm sayfalarını indexlesinler."
Örnek 2
User-agent: * Disallow: /
Kodumuzu inceleyelim. Disallow özelliğinin '/' işaretiyle ayarlanması;
"Tüm arama motorları web sitenizin hiçbir sayfasını indexlemesinler."
Örnek 3
User-agent: * Disallow: /admin/
Bu kodların anlamı: Disallow özelliğine '/admin/' eklenmiş, bunun anlamı şudur.
"Tüm arama motorları için "/admin/" klasörü ve içindeki hiçbir dosya indexlenmesin, geriye sitedeki tüm sayfalar indexlenebilsin."
Yani www.websiteniz.com/admin/panel.aspx gibi bir bölümü arama motoru indexlemeyecektir.
Örnek 4
User-agent: * Disallow: /panel/default.aspx
Bu kodların anlamı: Tüm arama motorları panel klasörü içindeki default.aspx dosyamızı indexlemesinler, fakat panel klasörü içindeki diğer tüm sayfaları indexleyebilirler.
Örnek 5
User-agent: Googlebot Allow: /fotograf/piknik/ Disallow: /fotograf/
Bu kodların anlamı: Tüm arama motorlar, fotograf klasörü içindeki "piknik" klasörünü indexleyebilirler fakat geri kalan hiçbir dosyayı indexleyemezler.
Robots.txt dosyası nasıl oluşturulur
KAYNAKLAR